
A RAG rendszer a Retrieval-Augmented Generation rövidítése. Ezzel a technológiával ma sok cég saját AI asszisztenst épít. A logika egyszerű. Nem a ChatGPT általános tudására támaszkodunk. A rendszer a saját szerződéseinkre, HR-szabályzatainkra és tudásbázisunkra épül. Az LLM csak arra válaszol, amit ezekben talál. A válasz mindig ellenőrizhető. Forrással hivatkozott. Érzékeny adat nem kerül ki a cégből. Ebben a cikkben bemutatjuk, mit jelent a RAG rendszer magyar nyelven. Milyen kihívások jönnek elő. És hogyan építhet olyan megoldást, ami a saját vállalati tudásbázisán dolgozik.
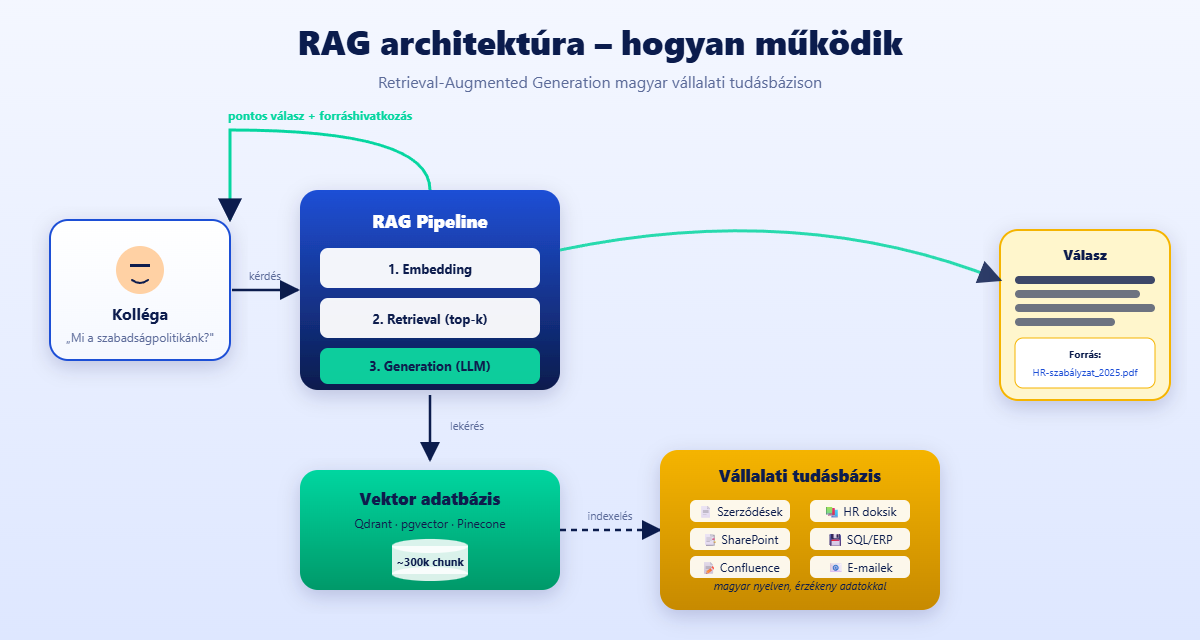
Mi az a RAG rendszer magyar nyelven?
A RAG rendszer három lépésből áll. Először a kérdést vektorrá alakítjuk. Ezt embeddingnek hívjuk. Ezzel megkeressük a tudásbázis releváns részleteit a vektor adatbázisban. Ez a retrieval. Végül az LLM megkapja a részleteket. Csak ezekre támaszkodhat a válaszban. Ez a generation.
A magyar bevezetés azért különösen fontos. A nemzetközi, angolul tanított modellek pontatlanok a mi szakmai szövegeinken. Az ok: ragozás, karakterkészlet, szakzsargon. A jól felépített magyar RAG pipeline viszont pontosan válaszol. Például: „mekkora az apasági szabadság a szerződésünk szerint?„. Olyan minőségben, mint egy tapasztalt HR-es kolléga. 15 másodperc alatt. A forrás pontos megjelölésével.
Milyen üzleti problémákat old meg a RAG rendszer?
A legtöbb magyar cégnél ugyanazok a panaszok jönnek elő. „Nem találjuk az iratokat a SharePointon.” „Az új belépő három hónapig keresgél.” „Mindenki a HR-est zavarja.” Egy jól felépített RAG rendszer ezekre azonnal válaszol. A cég saját dokumentumai alapján. A szolgáltatás 24/7 elérhető.
A tipikus hasznosítási területek változatosak. HR önkiszolgáló asszisztens. Belső jogi és szerződés-kereső. Ügyfélszolgálati tudásbázis. Mérnöki dokumentációs kereső. Vezetői kérdés-válasz. Ez utóbbi akár ERP adatokat is lekérdezhet természetes nyelven.
Az előny nem csak kényelem. Egy 200 fős cégnél egy alkalmazott heti 2-3 órát keres infókat. Ezt 60-80%-kal lecsökkenteni nagy érték. Havi szinten többszázezer forintos megtakarítás. Ezt akkor is megkapjuk, ha a RAG csak az első 3 dokumentumrészletet mutatja meg. A megfelelő forrással együtt.

Magyar nyelvi kihívások – és amit mi másképp csinálunk
Egy RAG rendszer pontossága az embedderen áll vagy bukik. A jó embedder érti a ragozott, ékezetes magyar szöveget. Az angol modellek itt gyengén teljesítenek. Például a text-embedding-ada-002 csak angolul jó. Magyarul 20-35%-kal gyengébb. A multi-lingvális változatok jobbak. Ilyen a multilingual-e5 és a bge-m3. Ezeket célzottan hangolni is lehet.
A magyar környezetben más kihívások is vannak. PDF-ek OCR-je helyes ékezetekkel. Szakzsargon kezelése. Például „NAV-ÁFA-ellenőrzés” vagy „TB-visszatérítés„. Cégspecifikus rövidítések. És az adatvédelem. Érzékeny dokumentumok nem kerülhetnek külföldi felhőbe. A megoldás GDPR-kompatibilis, EU régiós vagy on-premise telepítés.
A technológiai stack választása is fontos. Induljon a LangChain hivatalos RAG dokumentációjából. Ezt egészítse ki magyar specifikumokkal. Embedder, OCR, chunking, domain szótár. A vektor adatbázis is kulcskérdés. A pgvector a PostgreSQL-re épül. DBA-képes környezetekben ideális. A Qdrant self-hostolható és gyors. Felhős környezetben a Pinecone és az Azure AI Search is jó. Feltéve, hogy az adat EU régióban marad.

Így zajlik egy RAG bevezetési projekt
A BerényiSoft Kft. csapata 6-10 hét alatt juttat el egy ügyfelet az első éles verzióig. Magyar vállalati környezetben. A folyamat 5 szakaszból áll.
1. Felmérés. Azonosítjuk a 3 legfontosabb use-case-t. Feltérképezzük az adatforrásokat. 2. Előkészítés. Tisztítjuk a dokumentumokat. Chunking és embedding magyar modellel. 3. Pipeline építés. Vektor adatbázis, retrieval és LLM integráció. Prompt-tuning. 4. Értékelés. Saját magyar tesztkészlet. Hallucinációmérés. Visszamérhető pontosság. 5. Élesítés. SSO és jogosultságok. Monitoring. Felhasználói visszajelzés beépítése.
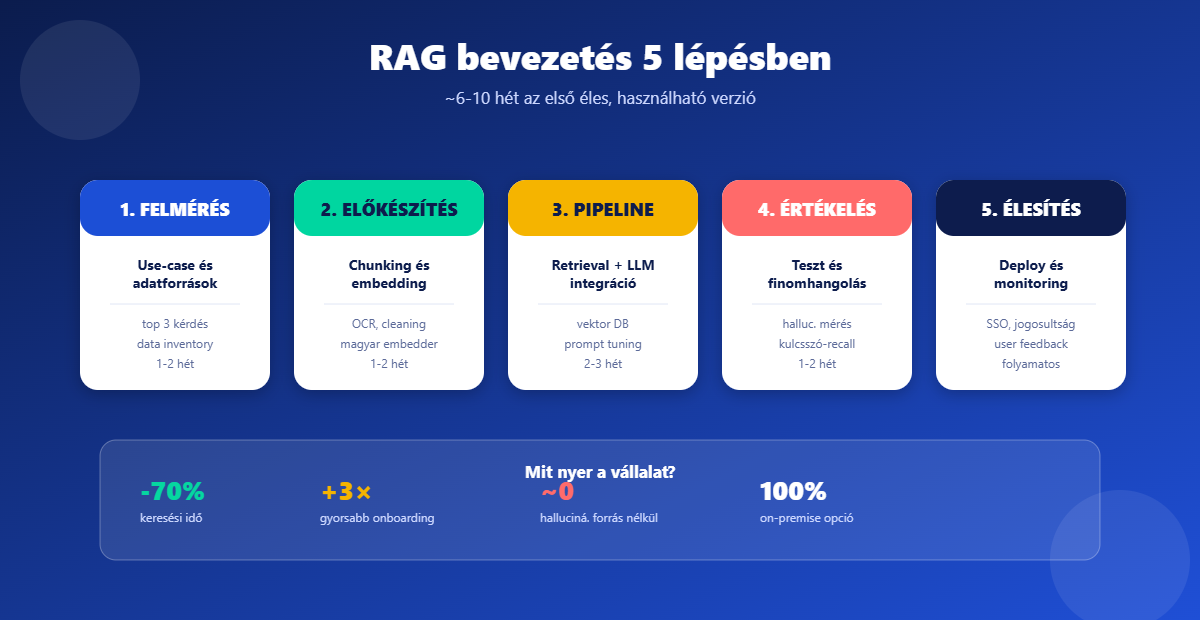
A folyamat minden lépése számít. Ha az embedder rossz, romlik a minőség. Ha a chunking túl nagy, a találatok pontatlanok. Ha nincs saját tesztkészlet, nem látjuk a javulást. A RAG ilyenkor „magabiztos, de rossz” választ ad. A felhasználók gyorsan elveszítik a bizalmat. Ezért érdemes tapasztalt partnerrel kezdeni. Nem a technológia a nehéz. Hanem a sok apró döntés. A BerényiSoft AI tanácsadási szolgáltatása ezen az úton végigvisz. A kezdeti koncepciótól a folyamatos optimalizálásig.
Összefoglalás
A RAG rendszer ma a legpragmatikusabb út. A cég a saját adatain építhet AI asszisztenst. Nincs adatszivárgás. Nincs hallucináció. Nincs fekete doboz. Magyar környezetben a siker kulcsa több tényező. Jó multi-lingvális embedder. Magyar OCR pipeline. Domain-specifikus szótár. On-premise vagy EU régiós telepítés. Aki időben lép, versenyelőnyt szerez 2026-ra. Ráadásul olyat, amit nem lehet lemásolni. Mert az Ön saját vállalati tudásbázisán alapul.